Pandas Read Txt File Into Different Columns
Pandas reads the official documentation provided by the file
Before using pandas to read files, the necessary content must be the official document, the official certificate access accost
http://pandas.pydata.org/pandas-docs/version/0.24/reference/io.html
The document operation belongs to Input/Output in pandas, which is as well the IO operation. The basic API is in the above URL. Next, the core of this article will let you understand some commonly used commands
pandas read txt file
Reading the txt file requires determining whether the txt file conforms to the basic format, that is, whether there are special separators such as \\t, `, , `, etc. >
The general txt file grows similar this
Example of a txt file
The following file is a space interval
1 2019-03-22 00:06:24.4463094 Chinese test
ii 2019-03-22 00:06:32.4565680 Demand to edit encoding
iii 2019-03-22 00:06:32.6835965 ashshsh
4 2017-03-22 00:06:32.8041945 eggg Read commands tin exist read_csv or read_table.
import pandas as pd
Df = pd.read_table("./test.txt")
Impress(df)Import pandas every bit pd
Df = pd.read_csv("./test.txt")
Print(df)
Nonetheless, note that the data content read in this place is a DataFrame type of 3 rows and one column, and does not get 3 rows and 4 columns according to our requirements
import pandas as pd
Df = pd.read_csv("./test.txt")
Print(type(df))
Print(df.shape)<class &39;pandas.cadre.frame.DataFrame&39;>
(3, 1)
read_csv function
Default: Loads delimited information from files, URLs, file new objects, and the default separator is a comma.
The in a higher place txt documents are non separated by commas, then you need to increase the sep separator parameter when reading
df = pd.read_csv("./test.txt",sep=&39; &39;) Parameter description, official Source: https://github.com/pandas-dev/pandas/blob/v0.24.0/pandas/io/parsers.pyL531-L697
Chinese description and primal feature cases
is specified
| parameters | Chinese interpretation |
|---|---|
| filepath_or_buffer | tin be a URL, available URL types include: http, ftp, s3 and files, local file read case: file://localhost/ Path/to/tabular array.csv |
| sep | str type, default ',' specifies the separator. If yous do not specify a parameter, yous will try to divide them with a comma using the default value. The separator is longer than i character and is non '\\s+' and will use the Python parser. And ignore the comma in the data. Regular expression example: '\\r\\t' |
| | Delimiter, alternate delimiter (if this parameter is specified, the sep parameter is invalid) By and large not used |
| | True or False Default Fake, using a infinite every bit a separator is equivalent to spe='\\s+'. If this parameter is chosen, delimite will non work |
| header | Specify the first few lines every bit cavalcade names (ignoring the comment lines), if no column names are specified, the default header=0; if the column name header=None |
| names | Specify the column proper name. If the file does non incorporate a header row, it should expressively signal header=None , and the header can be a list of integers, such equally [0, ane, 3]. Unspecified intermediate rows will exist deleted (for example, skip 2 rows in this instance) |
| index_col(instance 1) | The default is None. Use the column name equally the row label for the DataFrame. If a sequence is given, use MultiIndex. If you read a file, the file has a delimiter at the finish of each line. Consider using index_col=Fake to brand panadas use the offset column as the name of the line. |
| usecols | Default None can apply column sequences or column names such every bit [0, 1, two] or ['foo', 'bar', 'baz'] , apply this Parameters can speed upwardly loading and reduce memory consumption. |
| squeeze | The default is False. In the example of True, the returned type is Serial. If the data is parsed and contains but one line, render Series#td> |
| prefix | The prefix of the automatically generated column proper noun number, such as: 'X' for X0, X1,... is valid when header =None or if no header is set. |
| mangle_dupe_cols | The default is Truthful, and the repeated columns will be designated as 'Ten.0'...'X.North' instead of 'X'...'10'. If you pass in Imitation, there will be duplicate names in the column, which will cause the data to be overwritten. |
| dtype | Example: {'a': np.float64, 'b': np.int32} Specify the information type for each column, a, b for the column name |
| engine | The analytics engine used. Yous can choose C or Python, the C engine is faster but the Python engine has more than features. |
| converters (instance two) | Set the processing part of the specified column, yous can use the "quote number" or "cavalcade name" for column designation |
| true_values/ false_values | The actual application scenario was non plant, Remarks, post-improvement |
| skipinitialspace | Ignore spaces after delimiters, default faux |
| skiprows | Defaults None The number of rows to ignore (from the beginning of the file), or a list of line numbers to skip (starting at 0) |
| skipfooter | Ignore from the end of the file. (c engine does not support) |
| nrows | How many rows of data are read from the file, the number of rows that need to be read (from the beginning of the file header) |
| na_values | null definition, past default, 'Due north/A', 'N/AN/A', 'NA', '-i.IND', '-ane. QNAN', '-NaN', '-nan', '1.IND', 'one.QNAN', 'N/A', 'NA', 'Nada', 'NaN', 'n/a', ' Nan', 'zip'. Both behave as NAN |
| keep_default_na | If the na_values parameter is specified and keep_default_na=Simulated, the default NaN volition be overwritten, otherwise add together |
| na_filter | Check for missing values (empty strings or null values). For large files, there is no Northward/A nix in the dataset, using na_filter=False tin can improve read speed. |
| verbose | Print out the output information of various parsers, for example: "Number of missing values in non-numeric columns". |
| skip_blank_lines | If True, skip blank lines; otherwise, tape as NaN. |
| parse_dates | There are the following operations 1. boolean. True -> parsing index ii. list of ints or names. eg If [1, 2, 3] -> Parse the values of columns ane, 2, and 3 equally separate engagement columns; iii. list of lists. eg If [[one, 3]] -> Combine 1, 3 columns as a date column < Br> 4. dict, eg {'foo' : [one, three]} -> Combine the i,iii columns and requite the merged column a proper name of "foo" |
| infer_datetime_format | If gear up to Truthful and parse_dates is available, then pandas will attempt to convert to a date type, and if information technology can be converted, convert the method and parse information technology. In some cases it will be 5 to x times faster |
| keep_date_col | If you join multiple columns to parse dates, continue the columns participating in the join. The default is False |
| date_parser | The function used to parse the date. By default, dateutil.parser.parser is used for the conversion. Pandas tries to parse in three dissimilar ways, and if you accept a problem, apply the next method. 1. Use ane or more than arrays (specified by parse_dates) equally parameters; two. Connect the specified multi-cavalcade string every bit a column every bit a parameter; iii. Call the date_parser function once per line to parse a Or multiple strings (specified by parse_dates) as arguments. |
| dayfirst | date blazon in DD/MM format |
| iterator | Returns a TextFileReader object to procedure the file block by block. |
| chunksize | File block size |
| compression | Directly use compressed files on disk. If you use the infer parameter, employ gzip, bz2, zero or unzip the file with the suffix ".gz", '.bz2', '.zip', or 'xz'. Otherwise, do non extract it. If you employ aught, the ZIP package China must incorporate only i file. Set to None to not decompress. |
| The new version 0.18.i supports goose egg and xz decompression | |
| thousands | Thousands of symbols, default ',' |
| decimal | decimal point symbol, default '.' |
| lineterminator | Line separator, only used under C parser |
| quotechar | Quotation marks, used as characters to place the beginning and interpretation, the separator within the quotes will be ignored |
| quoting | Command the quotes constants in csv. Optional QUOTE_MINIMAL (0), QUOTE_ALL (1), QUOTE_NONNUMERIC (2) or QUOTE_NONE (3) |
| doublequote | Double quotes, when single quotes take been defined, and the quoted argument is not QUOTE_NONE, use double quotes to indicate that the element inside the quote is used every bit an chemical element. |
| escapechar | When pricing is QUOTE_NONE, specify a character so that it is not subject area to the separator limit. |
| comment | Identifies that extra lines are not parsed. If the character appears at the get-go of the line, this line will be ignored. This parameter can only be ane character. Blank lines (like skip_blank_lines=True) comment lines are ignored past header and skiprows. For case, if you specify comment='' to parse 'empty\ a,b,c\ i,2,three' with header=0 then the issue will be 'a,b,c' as the header |
| encoding | Encoding method, specifying the character set type, usually specified as 'utf-8' |
| dialect | If no specific language is specified, it is ignored if sep is greater than one character. Encounter the csv.Dialect documentation specifically |
| error_bad_lines | If a row contains as well many columns, the DataFrame will non be returned by default. If gear up to false, the row volition be rejected (but available nether C parser) |
| warn_bad_lines | If error_bad_lines =False and warn_bad_lines =True then all "bad lines" will be output (only bachelor nether C parser) |
| low_memory | The cake is loaded into memory and parsed in low memory consumption. However, type confusion may occur. Make sure the type is not confusing and y'all need to set it to False. Or use the dtype parameter to specify the type. Note that using the chunksize or iterator parameter to block reads will read the entire file into a Dataframe, while ignoring the type (tin can only be valid in the C parser) |
| delim_whitespace | New in version 0.18.ane: Valid in Python parser |
| memory_map | If a file path is provided for filepath_or_buffer, the file object is mapped directly to retentivity and the data is accessed directly from there. Utilise this option to better performance because there is no longer any I/O overhead, and this way you can avoid file IO operations once more |
| float_precision | Specify the converter that the C engine applies to floating point values |
This department is part of the reference weblog https://world wide web.cnblogs.com/datablog/p/6127000.html Thanks to the blogger for the translation, O(∩_∩)O Haha~
Case ane
index_col use
Kickoff prepare a txt file. The biggest problem with this file is that there is a ',' at the terminate of each line. Explain as prompted. If there is a separator at the end of each line, in that location volition be issues, but it is found during the actual test. With the names parameter, the outcome can appear
goof,one,ii,3,ddd,
u,1,iii,4,asd,
As,df,12,33, Write the following lawmaking
df = pd.read_csv("./demo.txt",header=None,names=[&39;a&39;,&39;b&39;,&39;c&39;,&39; d&39;,&39;east&39;])
Impress(df)Df = pd.read_csv("./demo.txt",header=None,index_col=False,names=[&39;a&39;,&39;b&39;,&39;c&39;,&39;d&39;,&39;e&39; ])
Impress(df)
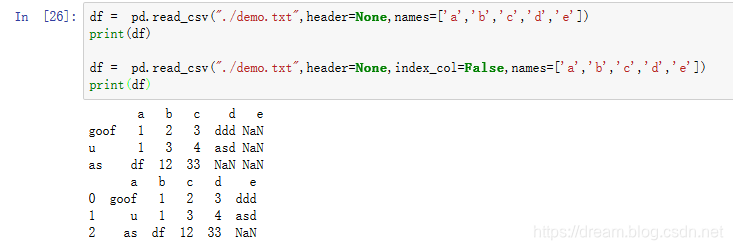
In fact, the significance is not actually great, and the document may non limited his specific role. Let's talk virtually the mutual use of index_col
When reading a file, if the index_col column index is non set, the integer index starting from 0 is used by default. When y'all operate on a row or column of a table, you will discover that at that place will always be ane more than column starting at 0 when saving to a file. If you set the index_col parameter to prepare the column index, this problem will not occur.
Case 2
converters Fix the processing function of the specified column, you can utilize the "quote number" or "cavalcade name" for column designation
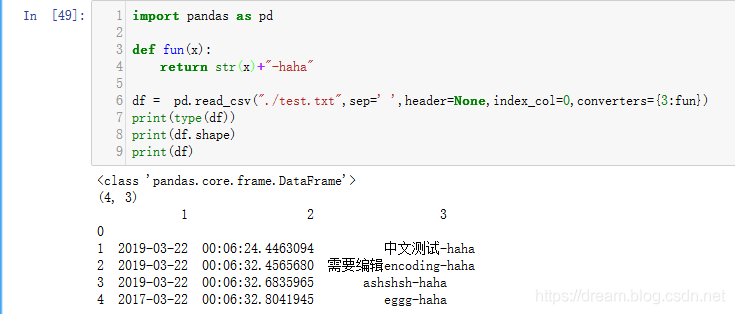
import pandas as pdDef fun(x):
Return str(10)+"-haha"
Df = pd.read_csv("./examination.txt",sep=&39; &39;,header=None,index_col=0,converters={3:fun})
Print(type(df))
Print(df.shape)
Print(df)
Common problems in the process of read_csv function
- When some IDEs use Pandas' read_csv function to import data files, if the file path or file name contains Chinese, an error volition be reported.
Workaround
import pandas as pd
Df=pd.read_csv(&39;F:/exam folder/test data.txt&39;)
f=open(&39;F:/test folder/test data.txt&39;)
Df=pd.read_csv(f) -
Exclude some lines Use the parameter skiprows. Its role is to exclude a line.
Notation that the first 3 rows are skiprows=3. The third row is skiprows=[3]
-
For irregular separators, employ regular expression to read the file
The separator in the file is a space, then we only need to ready sep=" " to read the file. When the separator is non a single infinite, perhaps there is a infinite and there are multiple spaces. If yous still utilise sep=" " to read the file at this fourth dimension, you may get a very strange information, because it will Spaces are besides used every bit data.
information = pd.read_csv("information.txt",sep="\\s+") -
If there is a Chinese encoding error in the file being read
Need to set the encoding parameter
-
Adding indexes to rows and columns
Add column index with parameter names, add row index with index_col
read_csv This control has a fair corporeality of arguments. Near are unnecessary because most of the files you download accept a standard format.
read_table part
The basic usage is the same, the difference is the separator separator.
Csv is a comma-separated value that only correctly reads data that is split with ",". read_table defaults to '\\t' (that is, tab) to cut the data fix
read_fwf function
Read files with fixed width columns, such as files
id8141 360.242940 149.910199 11950.7
Id1594 444.953632 166.985655 11788.4
Id1849 364.136849 183.628767 11806.2
Id1230 413.836124 184.375703 11916.eight
Id1948 502.953953 173.237159 12468.iii The read_fwf command has 2 additional parameters to gear up
colspecs :
You demand to requite a listing of tuples. The list of tuples is a semi-open up interval, [from, to). By default, it will infer from the first 100 rows of data.
Instance:
import pandas as pd
Colspecs = [(0, half-dozen), (8, 20), (21, 33), (34, 43)]
Df = pd.read_fwf(&39;demo.txt&39;, colspecs=colspecs, header=None, index_col=0) widths:
Use a width listing directly instead of the colspecs parameter
widths = [6, 14, 13, 10]
Df = pd.read_fwf(&39;demo.txt&39;, widths=widths, header=None) read_fwf is not used very frequently. Come across http://pandas.pydata.org/pandas-docs/stable/user_guide/io.htmlfiles-with-fixed-width-columns Learn
read_msgpack role
A new serializable data format supported past pandas, a lightweight portable binary format similar to binary JSON, which has loftier data space utilization and is written (serialized) Both the read and the read (deserialization) aspects provide proficient performance.
read_clipboard function
Read the data in the clipboard, which can be seen every bit the clipboard version of read_table. Useful when converting web pages to tables
The following Bug appears in this place
module 'pandas' has no attribute 'compat'
I updated the pandas and it works fine
There is also a place to compare the pits, when reading the clipboard, if you lot copy the Chinese, information technology is like shooting fish in a barrel to read the data
Solution
- Open site-packages\\pandas\\io\\clipboard.py This file needs to be retrieved by yourself
- Add together this to the line later text = clipboard_get() : text = text.decode('UTF-eight')
- Salvage and yous're ready to use
read_excel office
Still is the official document first lawmaking: http://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_excel.htmlpandas.read_excel
| parameters | Chinese interpretation |
|---|---|
| io | File form object, pandas Excel file or xlrd workbook. The cord may be a URL. URLs include http, ftp, s3 and files. For case, a local file can be written as file://localhost/path/to/workbook.xlsx |
| sheet_name | The default is that sheetname is 0, returning multiple tables using sheetname=[0,1], if sheetname=None is returning the full table. Annotation: int/string returns a dataframe, while none and list return a dict of dataframe, the table name is represented past a string, and the alphabetize table position is represented by an integer; |
| header | Specify the row every bit the column name. The default is 0, that is, accept the commencement row, the information is the information below the column name row; if the data does not contain the cavalcade proper noun, set the header = None; |
| names | Specify the proper name of the column, passing in a list of data |
| index_col | Specify the column equally an index cavalcade, or use u "strings". If you pass a listing, the columns will exist combined into a MultiIndex. |
| squeeze | If the parsed data contains only 1 column, return a Series |
| dtype | Data blazon of information or column, refer to read_csv |
| engine | If io is not a buffer or path, it must be set to identify io. Acceptable values are None or xlrd |
| converters | refer to read_csv |
| Other parameters | Bones and read_csv consistent |
pandas read excel file if the fault is reported, the general processing is
Error is: ImportError: No module named 'xlrd'
Pandas reads the excel file and requires a separate xlrd module to back up pip install xlrd
read_json function
| parameters | Chinese estimation |
|---|---|
| path_or_buf | A valid JSON file with a default value of None and a cord tin be a URL, such as file://localhost/path/to/table.json |
| orient (case 1) | The expected json string format, orient settings have the following values: 1. 'divide' : dict like {alphabetize -> [alphabetize], columns -> [columns], information -> [values]} 2. 'records' : list like [{column -> value},... , {column -> value}] 3. 'alphabetize' : dict like {alphabetize -> {column -> value}} 4. 'columns' : dict like {column -> {alphabetize -> value}} 5. 'values' : just the values array |
| typ | The format returned (series or frame), the default is 'frame' |
| dtype | Information type of data or column, refer to read_csv |
| convert_axes | boolean, endeavor to convert the axis to the correct dtypes, the default value is True |
| convert_dates | Listing of columns for parsing dates; if True, try parsing columns with similar dates, default is True Reference column tags it ends with '_at' , it ends with '_time', it begins with 'timestamp', information technology is 'modified', it is 'date' |
| keep_default_dates | boolean, default True. Parse the default appointment sample cavalcade if the date is resolved |
| numpy | Directly decodes into a numpy array. The default is Simulated; only numeric data is supported, only the characterization may be not-numeric. Also note that if numpy=True, JSON sorts MUST |
| precise_float | boolean, default Fake. Set up to enable the use of higher precision (strtod) functions when decoding strings to double values. The default (Fake) is a fast but less authentic born characteristic |
| date_unit | cord, the timestamp unit of measurement used to detect the conversion date. The default value is none. By default, the timestamp precision is detected, and if not required, the timestamp precision is forced to seconds, milliseconds, microseconds, or nanoseconds by i of 'southward', 'ms', 'united states of america', or 'ns', respectively. |
| encoding | json encoding |
| lines | Each line reads the file every bit a json object. |
If the JSON is unresolvable, the parser will generate one of ValueError/TypeError/AssertionError.
Case 1
- orient='split'
import pandas as pd
southward = &39;{"index":[i,ii,3],"columns":["a","b"],"data":[[i,three],[ii, five],[half-dozen,ix]]}&39;
Df = pd.read_json(south,orient=&39;carve up&39;) - orient='records'
Members are a dictionary listing
import pandas as pd
due south = &39;[{"a":1,"b":2},{"a":three,"b":four}]&39;
Df = pd.read_json(due south,orient=&39;records&39;) -
orient='index'
The alphabetize is the key, and the lexicon composed of the column fields is the key value. Such as:
south = &39;{"0":{"a":1,"b":2},"1":{"a":2,"b": four}}&39; -
orient='columns' or values tin exist inferred past yourself
For some Chinese translations, please refer to github> https://github.com/apachecn/pandas-medico-zh
read_json()Common Problems
Reading json file appears ValueError: Abaft information , JSON format problem
The original format is
{"a":i,"b":one},{"a":ii,"b":ii} Arrange to
[{"a":1,"b":1},{"a":ii,"b":2}] Or use the lines parameter and conform JSON to one data per line
{"a":ane,"b":i}
{"a":ii,"b":2} If in that location is Chinese in the JSON file, it is recommended to add the encoding parameter and assign 'utf-8', otherwise it will study an error
read_html function
| parameters | Chinese interpretation |
|---|---|
| io | Receive URLs, files, strings. The URL does not have https, endeavour to remove s and and then crawl to |
| match | Regular expression, returns a tabular array that matches the regular expression |
| flavor | The parser defaults to 'lxml' |
| header | Specify the row where the column header is located, list is a multiple index |
| index_col | Specify the cavalcade respective to the row header, list is a multiple index |
| skiprows | Skip the nth line (sequence mark) or skip n lines (integer marking) |
| attrs | backdrop, such as attrs = {'id': 'table'} |
| parse_dates | Parsing appointment |
Use the method, right click on the webpage, if you detect the tabular array, that is, tabular array can be used
Instance: http://data.stcn.com/2019/0304/14899644.shtml
<table class="..." id="...">
<thead>
<tr>
<thursday>...</th>
</tr>
</thead>
<tbody>
<tr>
<td>...</td>
</tr>
<tr>...</tr>
</tbody>
</table><table> : ascertain the tabular array
<thead> : ascertain the header of the table
<tbody> : ascertain the body of the form
<tr> : define the row of the tabular array
<th> : ascertain the header of the table
<td> : define table cells
Mutual Bug
The following error occurred: ImportError: html5lib not institute, please install it
Install html5lib, or use parameters
import pandas as pd
Df = pd.read_html("http://data.stcn.com/2019/0304/14899644.shtml",flavour =&39;lxml&39;) For more than reference source lawmaking, see > http://pandas.pydata.org/pandas-docs/stable/user_guide/io.html
Catastrophe
As of now, this blog has been completed. For pandas to read the file, I believe you lot should have an in-depth understanding. In the process of reading files from pandas, the most mutual problem is the Chinese trouble and the format problem. I promise that when you encounter it, it can be solved perfectly.
If you have any questions, I hope I can reply to y'all in the comments section. I look forward to working with yous. Web log Garden - Dream Eraser
Source: https://www.codestudyblog.com/cnb/0319174046.html
{kind=link}
Post a Comment for "Pandas Read Txt File Into Different Columns"